The question in one paragraph
Synthetic respondents do not replace focus groups. They replace specific parts of the work that focus groups were used for: fast aggregate directional reads, simulated conjoint, hard-to-recruit elite interviews, and pre-test screening. Humans remain essential for novel stimuli, variance, individual-level heterogeneity, non-Western markets, and B2B procurement reality. The winning stack uses both. Neither is sufficient alone.
Replace what, not replace everything. The honest answer is more useful than either of the two narratives the category is selling.
Where synthetic respondents actually win
Aggregate distribution on well-covered topics. Park et al.[1] built generative agents for 1,052 real people (interviewed each for two hours) and reproduced General Social Survey responses at 85 percent of the test-retest accuracy those same people produced with themselves two weeks later. That is the best external benchmark for the ceiling today. For questions similar to what is already in the training distribution, synthetic is close to human.
Economic game replications. Horton, Filippas, and Manning[2] showed LLMs qualitatively replicate Charness-Rabin fairness results, Kahneman 1986 fairness, and Samuelson-Zeckhauser endowment experiments. The directions match; the magnitudes are compressed.
Hard-to-recruit elites. Evidenza partners with Mars, EY, and Dentsu to run synthetic CMOs and CFOs. For audiences where real human recruitment takes weeks and costs thousands per interview, a synthetic panel is a directional screen that frees human time for the handful of real interviews worth paying for.
Fast screening and pre-test. A ten-thousand-agent synthetic study can narrow fifty creative variants down to the top five in an afternoon. Human testing then runs on the top five.
Subsegment boosts. Fairgen's Fairboost[3] synthesizes boosts for underrepresented subsegments in a real panel rather than replacing the panel wholesale. Different shape, narrower claim, more defensible.
Where humans still win
Novel stimuli out of distribution. Anything the model did not see during training. Post-cutoff creative. Genuinely new cultural moments.
Individual-level heterogeneity. Brand, Israeli, and Ngwe at HBS[4] found GPT-3.5 produced reasonable aggregate willingness-to-pay in conjoint for toothpaste and laptops but failed badly on individual-level heterogeneity. Means converge. Variance collapses. For strategy that depends on segment edge cases, this is a showstopper.
Variance and edge cases. The 2025 GRIT Insights Practice Report[5] found 67 percent of suppliers now embed generative AI, and data-quality concerns rose 40 percent year over year, largely attributed to synthetic respondents and survey fatigue. Conjointly's Samoylov called synthetic respondents "the homeopathy of market research"[6] and reported LLM-to-human attitude correlations of r≈0.10 on individual responses (about 1 percent of variance).
B2B procurement reality. A synthetic panel has never lost a committee vote to a legal review. Humans have.
Non-Western culture. The MRS Delphi Report[7] flagged systematic cultural bias against non-Western markets in training data. Translating English-trained models to Southeast Asian, Latin American, or African contexts produces lower agreement than the headline aggregate numbers suggest.
Tasting, smell, tactile, in-context behavior. Everything that needs a physical subject. Synthetic does not do shelf walkthroughs.
The vendor map
Simile (Stanford spinout, Index-led Series A at ~$100M, February 2026). Most academically rigorous framing. CVS Health as a named customer.
Aaru (Redpoint-led Series A at $1B headline valuation, December 2025). ARR reported under $10M. Correctly called the NY Democratic primary. Aggressive on valuation, thinner on published calibration.
Listen Labs (Sequoia-led, $27M in early 2025, then $69M at ~$500M after a viral billboard hiring stunt). Customer-obsession positioning.
Evidenza (London, bootstrapped). Claims 95 percent accuracy on synthetic responses. Mars, EY, and Dentsu partnerships.
Yabble (acquired by YouGov for £4.5M headline, August 2024). Now an AI analytics layer inside a traditional panel house.
Fairgen ($8M seed, May 2024). Synthesizes subsegment boosts rather than full panels. Different shape.
Incumbents. Qualtrics Edge Audiences (October 2025), Ipsos PersonaBots, Kantar and Cint synthetic panels. NielsenIQ's 2024 paper[8] positions synthetic respondents as augmentation, not replacement. That is the right framing.
The honest math
Park's 85 percent test-retest number and Conjointly's r≈0.10 are both real. They measure different things. Park measured aggregate-level agreement on GSS-like questions already in the training distribution. Conjointly measured individual-level correlation on bespoke survey questions. Both can be true simultaneously.
The failure mode most people miss is hyper-accuracy distortion. LLMs trained on typical-responder data will return compressed variance. Ten agents with nominally different demographics will give nine answers that look too similar. The aggregate mean is roughly right. The tails are missing.
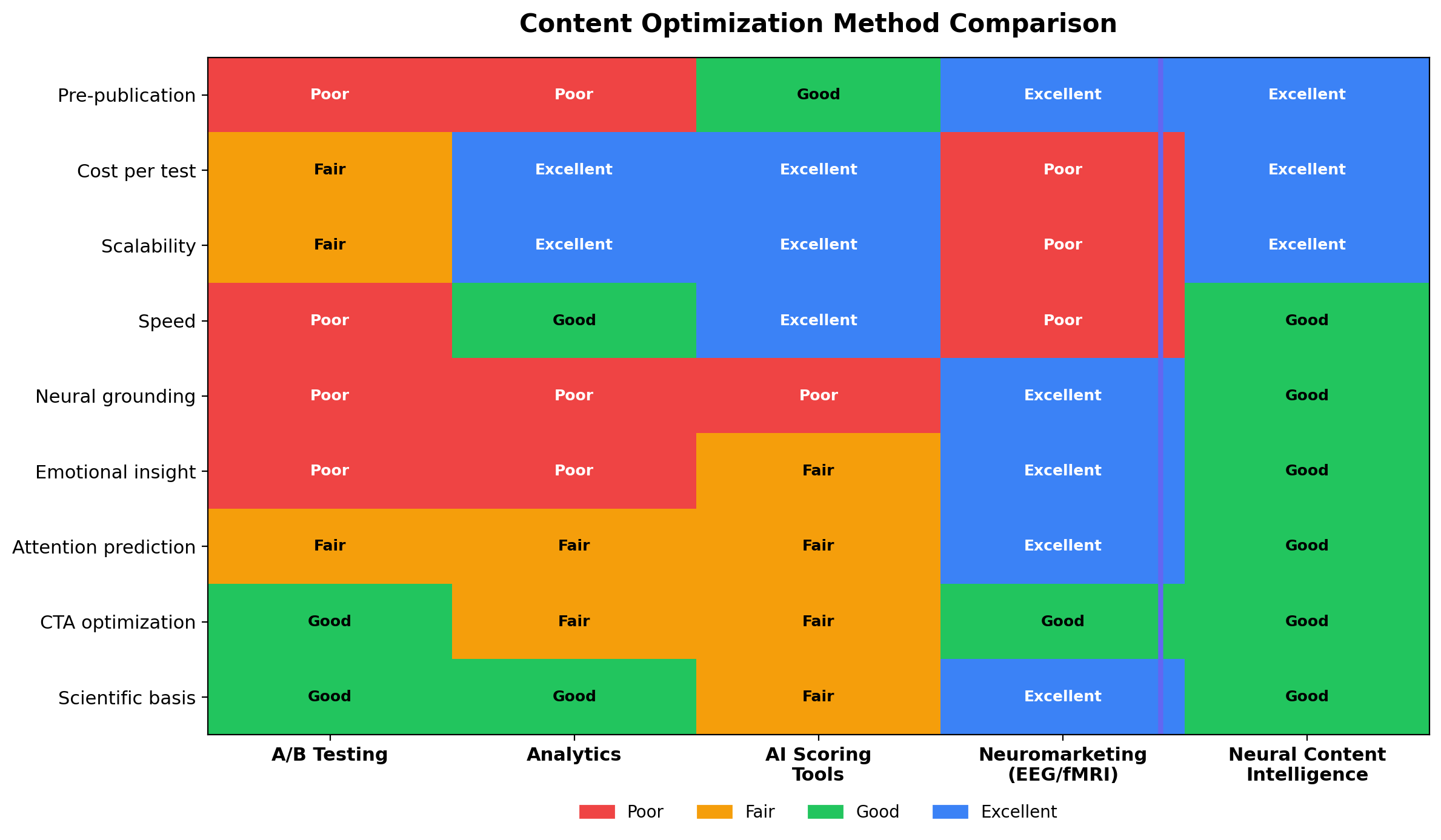
The blended stack
The workflow that uses both well:
- Pre-test synthetic at scale. Screen concepts, narrow the space.
- Field human qual where uncertainty is highest. Novel cultural territory. New audiences. B2B decision committees.
- Field synthetic again post-launch for longitudinal tracking where human recruitment would be prohibitive.
- Use content-intelligence infrastructure (see the four signals framework) to add neural, linguistic, cultural, and historical signals on top. Synthetic panels produce one family. Fusion produces the forecast.
What to ask a synthetic vendor before buying
- What is your training data cutoff? Anything after that date is out of distribution.
- What is your reported correlation against ground truth, at what aggregation level? Aggregate-level and individual-level are different numbers.
- Do you publish calibration studies? If not, why not.
- What failure modes do you explicitly disclose? A vendor that lists four is more credible than a vendor that claims zero.
- How do you handle non-English markets? Most don't well.
The category is young and the best vendors will answer these directly. The ones that dodge are the ones to avoid.
References
- 1Park et al. Generative agent simulations of 1,000 people. arXiv:2411.10109.
- 2Horton, Filippas, Manning. Homo silicus. NBER WP 31122.
- 3Fairgen (TechCrunch).
- 4Brand, Israeli, Ngwe. Using LLMs for market research. HBS WP 23-062.
- 5GRIT Insights Practice Report 2025.
- 6Conjointly. Synthetic respondents are the homeopathy of market research.
- 7MRS Delphi Report on synthetic respondents.
- 8NielsenIQ. The rise of synthetic respondents. 2024.
- 9Argyle et al. Out of one, many: using language models to simulate human samples. Political Analysis 2023.
- 10ESOMAR Global Market Research 2025.